



How I know the 2020 presidential election was stolen

Today I plan to lay the foundations for a series of posts connecting the 2020 and 2024 presidential elections. I will examine issues and candidates as dispassionately as I can. I will not offer red meat, clickbait, empty slogans, or loyalty to anyone or anything other than God, the American Declaration of Independence, and the American Constitution. You may agree with some things I write and disagree with others. That does not turn us into enemies unless you will it. If I err in any assertion of fact, please correct me. If I leave out any key assumptions, point them out. Ad hominem arguments and epithets undermine your own credibility, so avoid them.
I am reasonably knowledgeable about the construction of predictive models. I teach the subject, and have studied many data sets. Based on my experience, the set of 17 presidential elections from 1952 to 2016 is rather well-behaved. The predictive models I constructed for these elections are as good as any I have seen. I do not predict the electoral outcome, but rather the national popular vote. My models do not make use of polls, but rather other predictors which are known and fixed in advance of the election.
As with all statistical models, there is some degree of uncertainty associated with the prediction. A point prediction - a single number - is rarely realized in fact. We usually offer an interval prediction with an associated confidence level, such as 95%, the most common. This tool allows us to estimate the rarity or surprise factor associated with an unusual observation known as an outlier.
I will roll out my predictive models gradually over the coming year, as the news warrants it, to predict the 2024 presidential election national popular vote. Right now, I want to examine the results of my best predictive models for 2020. There are two such models. One is my pre-election model, also known as ex ante. The other model is my post-election model, also known as ex post. This latter model verifies, or refutes, the accuracy of the official results.
The following graphic illustrates the predictions of my best pre-election model.
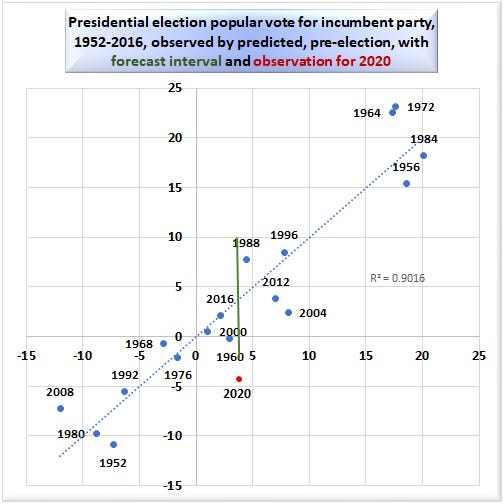
Along the horizontal axis, we measure the predicted margin in the national popular vote in favor of the party currently in the White House. The vertical axis measures the reported real margin in the national popular vote. The closer the points are to the diagonal line, the higher the predictive power of the model. This model has very good predictive power, as illustrated by R-squared = 90.16%. R-squared is between 0 and 100%; the higher the better. (For those who care, the p-value is < 0.000006, and the margin of error is 7.53%.)
Points above the line represent elections in which the incumbent party in the White House outperformed expectations, as in 1964, 1972, and 2008. Points above the line represent elections in which the incumbent party in the White House underperformed expectations, as in 2004. No point is more distant from the diagonal line than the 2020 election. For an election environment like 2020, 95% of results should fall within the green interval. EDIT: Trump underperforms expectations by 8% of the national popular vote.
It gets much worse when we include post-election information. Here is the graphic.
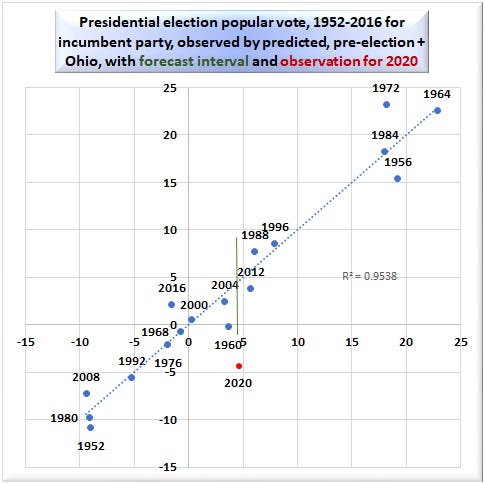
Now the value of R-squared climbs to an astonishingly high 95.38%. (The p-value is now < 0.0000006, and the margin of error shrinks to 5.39%.) Points are very close to the diagonal line, with one exception: 2020. The red dot for 2020 falls well outside the green 95% prediction interval. Indeed, I calculate that if the 2020 election were honest, the official result is one that would be seen only once in 20,676 years. EDIT: Trump now underperforms expectations by an incredible 8.5% of the national popular vote.
Cook’s distance is a statistical tool that measures the lack of conformity of individual observations to the pattern set by the remaining observations. It is a positive number, ideally less than 0.5 for well-behaved data. If it increases to a value between 0.5 and 1, this causes concern, and may prompt an investigation of the observation, to see if it was entered correctly. Values between 1 and 2 may even be subject to removal from the data set. I do not recall seeing Cook’s distance greater than 2 for other data sets and observations.
Here are the graphs of Cook’s distance for the 18 elections from 1952 through 2020, for my best pre-election and post-election models. See if you can spot the outlier.


For 2020, the respective values of Cook’s distance are about 10 and 15 in the two models. I have never seen numbers that big, ever. The chance of seeing such observations in the case of a truly honest election are less than one in five thousand.
I have discussed these observations with conservative friends who oppose Trump. They reply that we have no solid proof of how the election was allegedly stolen. This rejoinder is missing the point.
Suppose while taking a walk in the park, we come across a bloody body with stab wounds. We run to our friend to report a murder. The friend says, “You don’t know who committed the alleged murder; you have not identified the murder weapon or when the murder occurred. Since I don’t like the victim, I am going to deny that there even was a murder.”
Such reasoning is illogical. Clearly a crime did occur. Now it must be investigated to discover how it occurred and who perpetrated it. But you cannot deny the existence of the crime.
I take it as an assumption for the rest of my articles that the 2020 presidential election was indeed stolen, whether you support Trump or not. Having established this to my satisfaction, however, I admit to a worry that every election from now on is capable of being stolen as well. We should return to this issue.
Fascinating statistics Surak, if that level of anomaly occurred in any other area of business or government there would be a serious investigation.
The vast majority of projects can be plotted on an S curve and these give us clear indications about things like dumping money at the project conclusion or throwing money at a problem.
Thank you for sharing this. I was an election judge in the last 3 elections and the 2020 election in my very corrupt state (MN) showed all the signs of election tampering. Please continue to share as a full investigation of how this election was stolen must be conducted.